基本蜘蛛製作流程
在更新 1.5.0t / 1.2.0b 加入了蜘蛛,蜘蛛是什麼?
蜘蛛就是能自動爬網頁的東西,跟據不同的設定,能將各種網站爬成一本書來看。不過這不是做給一般人的啦,但也不是説不懂的話就沒戲唱。因為腳本對應的通常是整個網站 —— 也就是説,只要寫好一個腳本,那麼整個網站的書都可以隨便看了。腳本的製作時間通常為 15 分鐘 ~ 1 小時。熟練的話做一個腳本只要 5 分鐘吧。
基本需求
編寫腳本需具備以下條件:
- 基本的 Html 知識
- 懂得如何檢視網站的原始檔
- 正則表逹式 ( RegExp )
- ( 如有 ) JavaScript ( 進階編寫用,一般來説不懂也沒問題 )
- ( 如有 ) 玩 Minecraft 時喜歡組裝 Redstone circuit
- 超喜歡看書
- 超超喜歡看書
當然不是所有網站都行,但蜘蛛本來就沒有什麼特定的目標,所有動作都是自己設定的,所以限制當然就定在所給予的動作範圍內。這時候就需要各位的協助了,請告訴我那個網站不能爬,我會檢討這個網站並增加相應的動作,讓這個網站也能爬的。
那麼請讓我來講解一下蜘蛛的運作方式吧,按這個進入編輯器:
- 基本的 Html 知識
- 懂得如何檢視網站的原始檔
- 正則表逹式 ( RegExp )
- ( 如有 ) JavaScript ( 進階編寫用,一般來説不懂也沒問題 )
- ( 如有 ) 玩 Minecraft 時喜歡組裝 Redstone circuit
- 超喜歡看書
- 超超喜歡看書
當然不是所有網站都行,但蜘蛛本來就沒有什麼特定的目標,所有動作都是自己設定的,所以限制當然就定在所給予的動作範圍內。這時候就需要各位的協助了,請告訴我那個網站不能爬,我會檢討這個網站並增加相應的動作,讓這個網站也能爬的。
那麼請讓我來講解一下蜘蛛的運作方式吧,按這個進入編輯器:
界面

編緝頁主要分為 3 個部分:
1. 控制選單
從左至右分別是:
1. 步驟選單
2. 添加此步驟
3. 運行
4. 打開文件
5. 儲存
6. 另存新檔
1. 步驟選單
2. 添加此步驟
3. 運行
4. 打開文件
5. 儲存
6. 另存新檔
2. 步驟檢視
檢視蜘蛛的運作模式
基本步驟分別是
「網址列表」、「過濾」、「標籤」與「提取」
至版本 1.3.0b / 1.7.8t
動作已增加至八個,進階的步驟為
「腳本」、「網址生成」、「編碼」與「檢視結果」
基本步驟分別是
「網址列表」、「過濾」、「標籤」與「提取」
至版本 1.3.0b / 1.7.8t
動作已增加至八個,進階的步驟為
「腳本」、「網址生成」、「編碼」與「檢視結果」
3. 運作記錄
記錄運作的過程?
腳本的製作方針
根據網站的 html 製作出指示,從抓回來的網頁提取目錄、章節及內容。
( 於版本 1.3.0b 已經引入腳本分享,我也上載了幾個樣本上去,各位下載之後可以直接按右鍵選擇「編輯」查看是怎麼做的。另外也請各位湧躍分享和交流腳本的心得,整個平台我也是很努力做的。)
( 於版本 1.3.0b 已經引入腳本分享,我也上載了幾個樣本上去,各位下載之後可以直接按右鍵選擇「編輯」查看是怎麼做的。另外也請各位湧躍分享和交流腳本的心得,整個平台我也是很努力做的。)
抓我的 blog
由於 blog 就只有章節,沒有分卷,所以做起來算比較簡單。
那麼事不且遲,立刻就來 Inspect Element 吧!
那麼事不且遲,立刻就來 Inspect Element 吧!
1. 分辨出章節與分卷
章節普遍都會附上連結,而這個連結通常就是內容頁。
提取目錄時,我們需要將「章節的標題」與「文章的內容」連結起來。而這個「文章內容」通常就是一個超連結。當然可以直接對應內容,因為這個要做也很簡單,我會在後面稍加説明。
也就是説,我們要從這個 html 裏面提取出這樣的輸出:
第一個步驟當然是先將目錄頁面下載回來:
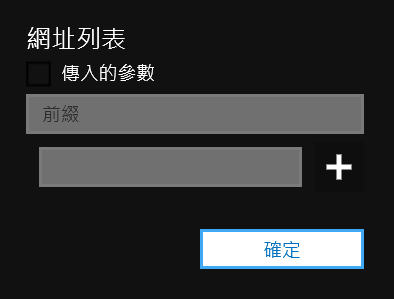
- 新增步驟「網址列表」
- 編輯並輸入 https://blog.astropenguin.net/article/latest ,並按「 + 」新增這個網址
第二個步驟是提取出剛才所説的輸出:
- 新增步驟「過濾」
- 表逹式輸入「 <div class="h_title fls"> <a href="/article/([^"]+)">([^<]+)</a> </div> 」,格式為「 [{2}] {1} 」
- 下面的是測試連結,點右邊的放大鏡則可檢視輸出
提取目錄時,我們需要將「章節的標題」與「文章的內容」連結起來。而這個「文章內容」通常就是一個超連結。當然可以直接對應內容,因為這個要做也很簡單,我會在後面稍加説明。
也就是説,我們要從這個 html 裏面提取出這樣的輸出:
[ 章節標題1 ] 連結1
[ 章節標題2 ] 連結2
[ 章節標題3 ] 連結3第一個步驟當然是先將目錄頁面下載回來:
- 新增步驟「網址列表」
- 編輯並輸入 https://blog.astropenguin.net/article/latest ,並按「 + 」新增這個網址
詳細資料:網址列表
前綴:
所以項目會加上這個前綴 ( 包括傳入的參數 )
傳入的參數:
跳過下面的列表,直接利用上一個步驟的輸出
所以項目會加上這個前綴 ( 包括傳入的參數 )
傳入的參數:
跳過下面的列表,直接利用上一個步驟的輸出
第二個步驟是提取出剛才所説的輸出:
- 表逹式輸入「 <div class="h_title fls"> <a href="/article/([^"]+)">([^<]+)</a> </div> 」,格式為「 [{2}] {1} 」
- 下面的是測試連結,點右邊的放大鏡則可檢視輸出
詳細資料:過濾
模式:
過濾分為兩種模式,一種是匹配 / 另一種則是取代。
詳見下圖:

匹配模式只會提取出匹配的項目,而取代則是輸出取代後的文字
過濾分為兩種模式,一種是匹配 / 另一種則是取代。
詳見下圖:
匹配模式只會提取出匹配的項目,而取代則是輸出取代後的文字
2. 編製目錄
編製目錄所需的步驟為「標籤」,這個步驟會跟據上一個步驟的輸出,分別套用章節與卷目的標題。
卷對應方式:
因為沒有分卷,這裏沒有用。就隨更寫上「鵬兄的 blog 」吧。
章節對應方式:
跟據上一步的輸出,我們可以從這個步驟再提取出兩個參數,一個是「章節標題」,另一個是「內容的連結」。
其實這個 章節對應 是一個小型的 匹配過濾模式,所以這個 blog 其實可以在三個步驟內完成啦,不過因為 過濾 是一個很重要的元素,我就分開來介紹了。
在上面點一下測試就可以檢視結果。
卷對應方式:
因為沒有分卷,這裏沒有用。就隨更寫上「鵬兄的 blog 」吧。
章節對應方式:
跟據上一步的輸出,我們可以從這個步驟再提取出兩個參數,一個是「章節標題」,另一個是「內容的連結」。
其實這個 章節對應 是一個小型的 匹配過濾模式,所以這個 blog 其實可以在三個步驟內完成啦,不過因為 過濾 是一個很重要的元素,我就分開來介紹了。
跟據上一個步驟:
[ 章節標題1 ] 連結1
[ 章節標題2 ] 連結2
[ 章節標題3 ] 連結3
表達式提取參數 "[ {1} ] {2}":
\[([^\]]+)\] (.+)
順序輸入:
標題: {1}
參數: {2}在上面點一下測試就可以檢視結果。
詳細資料:標籤
這個步驟的作用有點難說,這裏會將過濾好的章節卷目對應起來並製作目錄。
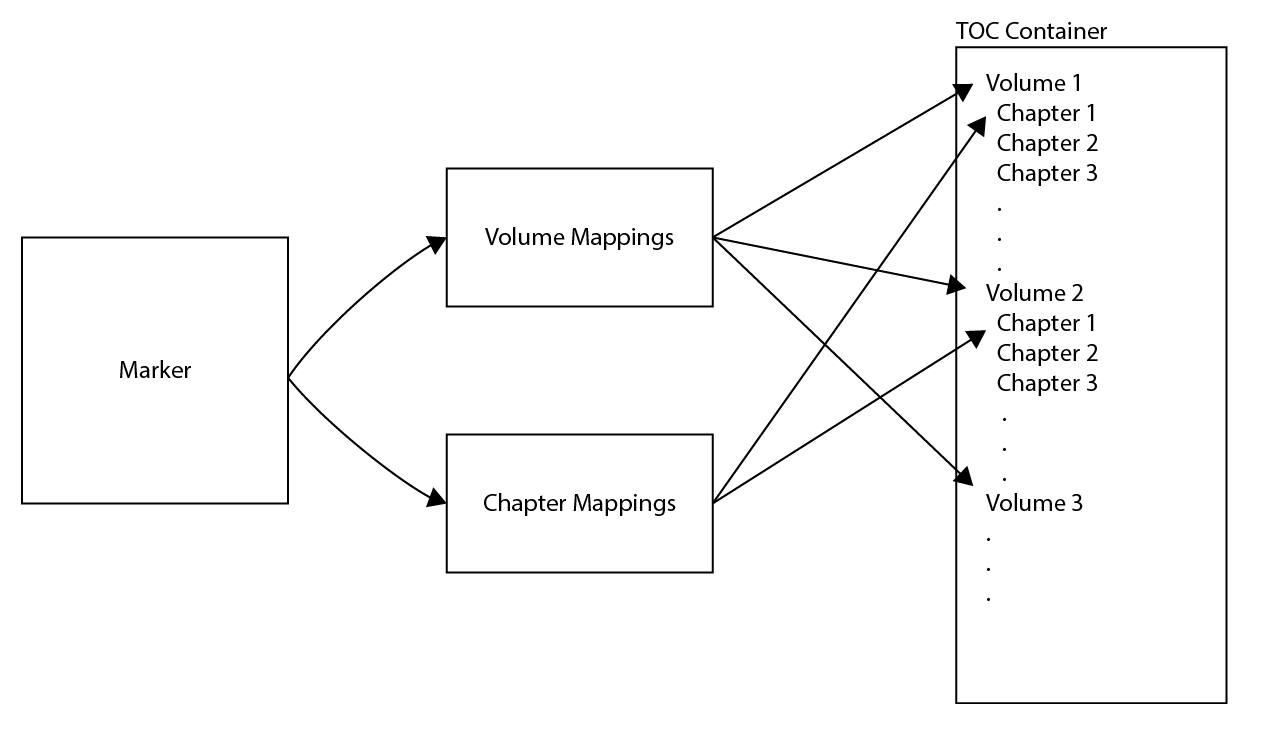
這個步驟會生成一個東西( TOC Container ),這個東西會一直沿用到程序運行完畢,下一個步驟,下下一個步驟都會嘗試找到這個東西來輸出內容。
也就是說可以將 Marker 拆成兩個部分,先下載卷目、對應,然後再下載章節、再進行對應也是可行的:
Volume Mappings ( 卷對應 )
Chapter Mappings ( 章節對應 )
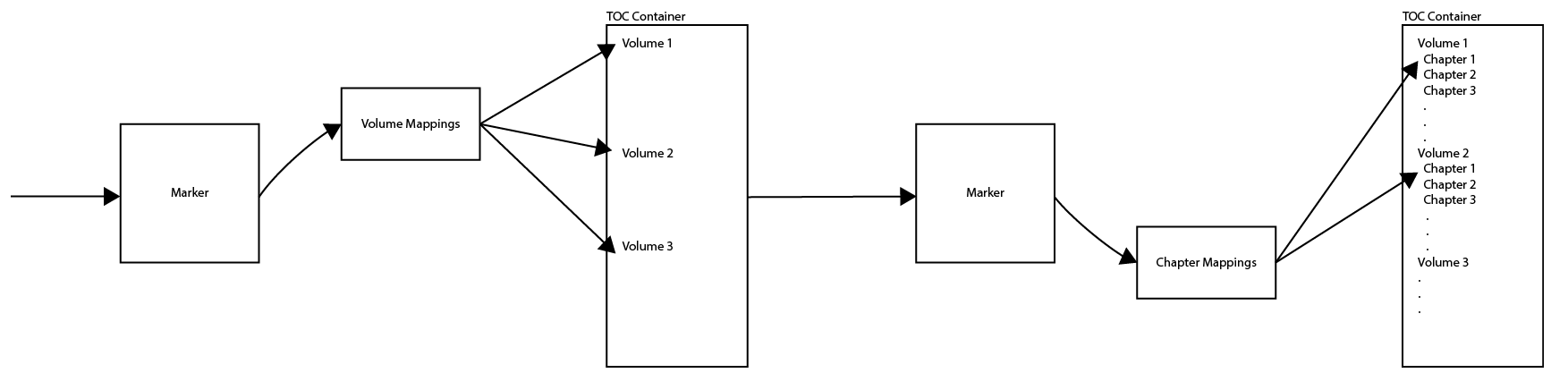
這個步驟會生成一個東西( TOC Container ),這個東西會一直沿用到程序運行完畢,下一個步驟,下下一個步驟都會嘗試找到這個東西來輸出內容。
也就是說可以將 Marker 拆成兩個部分,先下載卷目、對應,然後再下載章節、再進行對應也是可行的:
Volume Mappings ( 卷對應 )
Chapter Mappings ( 章節對應 )
3. 提取文章內容
在「標纖」步驟上,按「 ▪■ 」進入子程序
新增步驟「網址列表」:
- 引用「傳入的參數」
- 前綴輸入「 https://blog.astropenguin.net/article/ 」,這裏會將傳入標籤的參數加上這個前驟,下載並輸出文章內容。
來到這裏腳步基本上算是完成了,後面兩個步驟簡而言之就是將下載回來的東西過濾成可讀的純文字罷了。

子程序就是左邊的那個按鈕,右邊的就是「同步/異步」執行
子程序在這個部分就是執行子步驟,像下面的例子就指定了下載章節的子步驟。
異步執行
指不在同一個動作運行
作用是可以避免必須下載所有內容才可閱讀的問題,也減少了流量。
現階段這個功能只會在標籤步驟中起作用,其它步驟的子程序都是同步執行的。
新增步驟「網址列表」:
- 引用「傳入的參數」
- 前綴輸入「 https://blog.astropenguin.net/article/ 」,這裏會將傳入標籤的參數加上這個前驟,下載並輸出文章內容。
來到這裏腳步基本上算是完成了,後面兩個步驟簡而言之就是將下載回來的東西過濾成可讀的純文字罷了。
「子程序」及「異步程序」
子程序就是左邊的那個按鈕,右邊的就是「同步/異步」執行
子程序在這個部分就是執行子步驟,像下面的例子就指定了下載章節的子步驟。
異步執行
指不在同一個動作運行
作用是可以避免必須下載所有內容才可閱讀的問題,也減少了流量。
現階段這個功能只會在標籤步驟中起作用,其它步驟的子程序都是同步執行的。
4. 提取書頁資訊
這個步驟很直觀,就是提取書的各種訊息。用的都是表達式,也可以利用子程式及傳入的參數,我就不多説了。
樣本:
以下是抓我的 blog 的腳本

Mon Jan 11 2016 11:27:26 GMT+0000 (Coordinated Universal Time)
Last modified: Sun Apr 10 2022 08:22:55 GMT+0000 (Coordinated Universal Time)
Comments
wenku8网站好像已经复活了,跪求大大更新
faker
12:00 PM Mar 2016, 02 Wed
Reply
已經更新了哦?
斟酌 鵬兄
4:41 PM Mar 2016, 03 Thu
是wenku8现在可以用之前注册的账号登陆进网站,然后正常使用。具体可以见下面这个网址http://www.wenku8.com/index.php?fromuid=114413
faker
5:11 AM Mar 2016, 13 Sun
Reply
使用新版的 wen8 beta 需要動點腦筋
斟酌 鵬兄
10:54 AM Mar 2016, 13 Sun
Do you even comment?
website:
Not a valid website
Invalid email format
Please enter your email
*Name:
Please enter a name
Submit
抱歉,Google Recaptcha 服務被牆掉了,所以不能回覆了